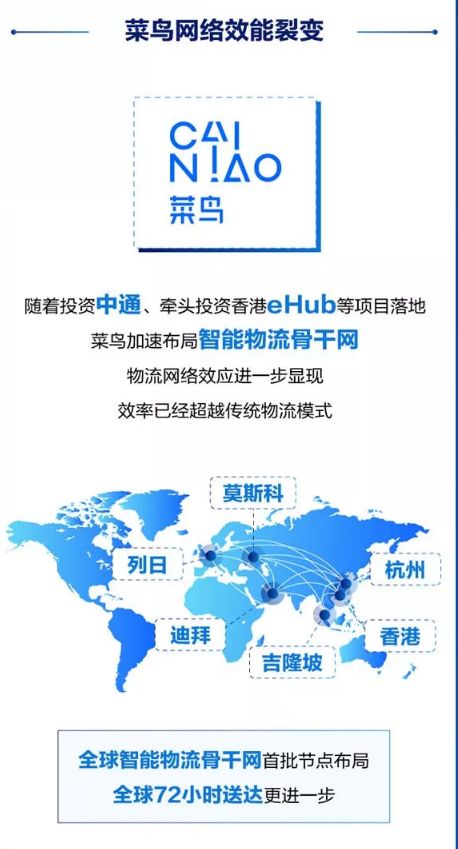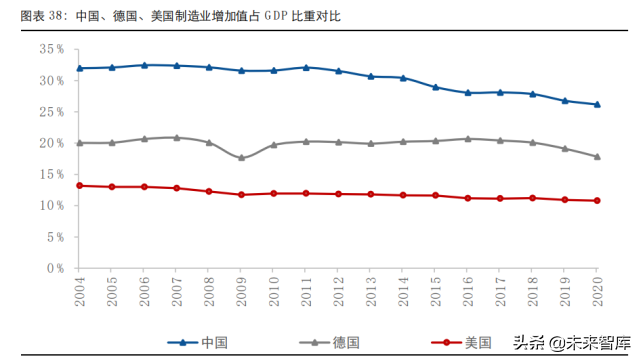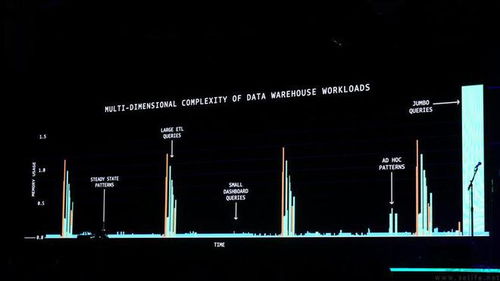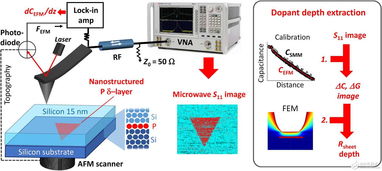
隨著量子計算技術(shù)的飛速發(fā)展,科學(xué)家們正在不斷探索新的方法以提升量子系統(tǒng)的性能與穩(wěn)定性。一項創(chuàng)新的成像技術(shù)應(yīng)運(yùn)而生,為量子計算領(lǐng)域的發(fā)展帶來了新的突破。這項技術(shù)不僅能夠?qū)崿F(xiàn)對量子比特狀態(tài)的精準(zhǔn)觀測,還能有效監(jiān)測量子設(shè)備中的微觀變化,從而為量子計算的優(yōu)化與應(yīng)用提供了強(qiáng)有力的技術(shù)支持。
傳統(tǒng)的量子系統(tǒng)監(jiān)測手段往往依賴于間接測量或復(fù)雜的數(shù)據(jù)分析,難以直觀捕捉量子態(tài)的實時變化。而新型成像技術(shù)通過高分辨率的圖像采集與處理,能夠直接可視化量子比特的量子態(tài)及其演化過程。這使得研究人員能夠更清晰地理解量子糾纏、量子疊加等現(xiàn)象,為量子算法的設(shè)計與調(diào)試提供了前所未有的便利。
該成像技術(shù)在量子計算設(shè)備的制造與維護(hù)中也展現(xiàn)出巨大潛力。通過對量子芯片表面的微觀結(jié)構(gòu)進(jìn)行成像分析,工程師可以及時發(fā)現(xiàn)并修復(fù)制造缺陷,提升量子比特的相干時間與操作精度。成像技術(shù)還能幫助監(jiān)測量子設(shè)備在運(yùn)行過程中的熱噪聲、電磁干擾等環(huán)境因素,為量子計算系統(tǒng)的穩(wěn)定運(yùn)行保駕護(hù)航。
在量子計算技術(shù)服務(wù)領(lǐng)域,這項成像技術(shù)的應(yīng)用將進(jìn)一步推動量子計算從實驗室走向產(chǎn)業(yè)化。服務(wù)提供商可以利用成像技術(shù)為客戶提供更精準(zhǔn)的量子系統(tǒng)診斷與優(yōu)化方案,加速量子計算在藥物研發(fā)、材料科學(xué)、金融建模等領(lǐng)域的實際應(yīng)用。隨著成像技術(shù)與量子計算的深度融合,我們有理由相信,量子計算將更快地實現(xiàn)商業(yè)化突破,為人類社會帶來革命性的變革。
這項為量子計算錦上添花的成像技術(shù),不僅填補(bǔ)了量子系統(tǒng)可視化監(jiān)測的空白,更為量子計算技術(shù)的發(fā)展開辟了新的道路。從基礎(chǔ)研究到技術(shù)服務(wù),它都將成為推動量子計算走向成熟的關(guān)鍵力量。